Windows Server 2016 Images mittels DSIM für OpenStack vorbereiten
Für unsere OpenStack DevCloud benötigten wir Images für OpenStack die mit cloudbase-init starten. Dazu gibt es bei Cloudbase ein GIT repository das die nötigen (Powershell) Scripte bereitstellt.
https://github.com/cloudbase/windows-openstack-imaging-tools
Als ich dies jedoch auf einem Windows 2012 R2 Server nach Anleitung ausführen wollte was das resultierende Image nicht startfähig. Es gab Warnungen dass DSIM nicht aktuell genug ist und anscheinend wurden auch die VirtIO Treiber nicht integriert.
Hier sind ein paar Schritte mit denen es dann geklappt hat:
a) Git4Windows installieren.
b) ein Arbeitsverzeichnis anlegen und die Image Tools dorthin auschecken:
mkdir c:\work
cd /d c:\work
git clone https://github.com/cloudbase/windows-openstack-imaging-tools.git
c) Aus einer Windows Server 2016 Installations-ISO das File sources\install.wim (5,6GB) extrahieren und nach c:\work\source\install.wim legen. (Ich habe dies mit einer Volume License ISO als auch dem 180 Tage Eval ISO erfolgreich gemacht)
d) Für Windows Server 2016 muss man eine DSIM Version verwenden die neuer ist. Dazu habe ich das Windows ADK für Windows 10, Version 1703 (Hardware Dev Center) auf dem Server installiert. Es gibt zwar auf der Webseite an dass dies nur für Windows 10 ist, jedoch war es in meinem Fall auch für Windows Server 2016 (Rollup CDs) notwendig.
e) nach der Installation ist es Wichtig das DSIM Verzeichnis dieses neuen Kits im Pfad vor dem Windows Systemverzeichnis zu haben (da dort eine alte DSIM Version gefunden wird). Man kann `(Get-Command dism.exe).Path` verwenden um zu sehen welches DISM verwendet wird. Ich habe es mir einfach gemacht und in das verwendete Powershell script einfach einen passenden Pfad gesetzt.
f) Im Beispielscript werden die RedHat VirtIO Treiber heruntergeladen, ich hatte die URL auf eine neue Version angepasst.
g) Das Offline Beispielscript habe ich angepasst dass es alle Verzeichnisse unter c:\work sucht, dass es nur ein 15GB Image anlegt (und weil dieses noch transportiert und gestartet werden muss habe ich es auch als QCow2 angelegt.
Hier das komplette script (auszuführen als privelegierter lokaler admin im Unterverzeichnis example):
"Windows Server 2016 Images mittels DSIM für OpenStack vorbereiten" vollständig lesen
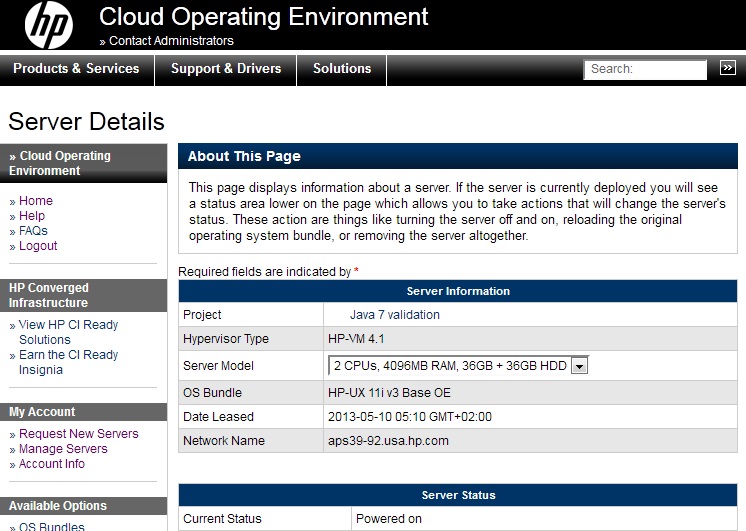 When ordering a new "Project" you have to give some details about the work you are planning to do (but I had actually never denied any request). Most of the work is related in trying out installer, shell scripts as well as Java dependencies.
Remote Shell Access
After ordering a Server (for example the medium configuration of HP-UX 11i v3 Data Center OE with 2 CPUs, 4GB RAM and 2 x 36GB HDD). After the server is provisioned (which takes about 12 minutes), you will receive an e-mail with the SSH key for root user. This SSH keyfile can be converted into a PuTTY .ppk file with the use of the PuttyGen Tool. The SSH access is the only open incoming network connection, so you need the SSH port forwarding feature available in PuTTY if you want to access or provide remote services.
The login is a bit slow, I discovered, that it helps to put the option
When ordering a new "Project" you have to give some details about the work you are planning to do (but I had actually never denied any request). Most of the work is related in trying out installer, shell scripts as well as Java dependencies.
Remote Shell Access
After ordering a Server (for example the medium configuration of HP-UX 11i v3 Data Center OE with 2 CPUs, 4GB RAM and 2 x 36GB HDD). After the server is provisioned (which takes about 12 minutes), you will receive an e-mail with the SSH key for root user. This SSH keyfile can be converted into a PuTTY .ppk file with the use of the PuttyGen Tool. The SSH access is the only open incoming network connection, so you need the SSH port forwarding feature available in PuTTY if you want to access or provide remote services.
The login is a bit slow, I discovered, that it helps to put the option 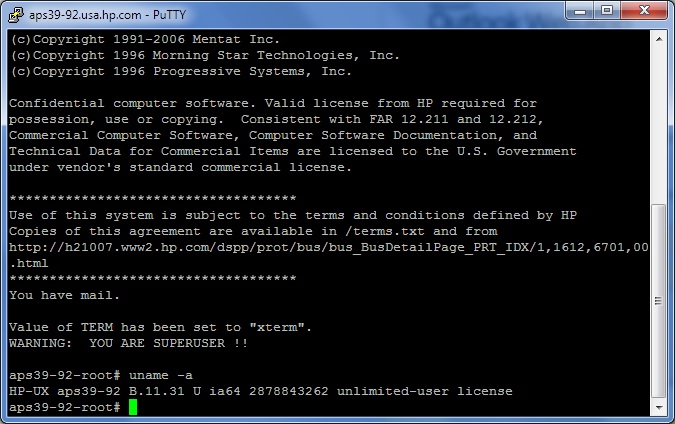 Installing Open Source Software
On the first startup the system is pretty basic, there are only some Open Source goodies installed in /usr/contrib. But it is missing for example a modern shell. We can fix this with the help of the
Installing Open Source Software
On the first startup the system is pretty basic, there are only some Open Source goodies installed in /usr/contrib. But it is missing for example a modern shell. We can fix this with the help of the 


 Beide haben grade aktuell Neuigkeiten zu vermelden: Google App Engine ist
Beide haben grade aktuell Neuigkeiten zu vermelden: Google App Engine ist